
Tenemos muchísimos datos y las técnicas necesarias para analizarlos, sacar insights de ellos y hacer predicciones cada vez más acertadas, así que los estadísticos podrían parecer innecesarios para seguir desarrollando modelos profundos a la vez que precisos. Pero, «spoiler alert»: necesitamos más que nunca especialistas de estadística precisamente para entender y mejorar nuestros modelos de datos. Aquí van algunas ideas al respecto con motivo del Día Mundial de la Estadística.
Es conocida la historia de la Segunda Guerra Mundial de cuando los ingenieros revisaban los aviones en busca de los agujeros de bala para saber dónde tenían que reforzar el fuselaje. La opción obvia era reforzar precisamente las zonas más dañadas, pero fue un estadístico, Abraham Wald, el que hizo cambiar el punto de vista: ¿y por qué no hay impactos en partes críticas como los motores? La conclusión era lógica: los aviones alcanzados en los motores no volvían, así que había que blindar esas áreas antes que otras en los aviones supervivientes. Esta anécdota clásica ilustra el enfoque único que aporta la estadística: ver lo que otros pasan por alto. Igual que Wald salvó vidas detectando un sesgo de supervivencia, hoy los estadísticos afrontan desafíos en un mundo inundado de datos masivos, IA y nuevas fuentes de información.

“Invisible touch”: el toque del estadístico
En el mundo del análisis de datos conviven muchos perfiles: informáticos, ingenieros, científicos de datos… ¿Qué pinta un “estadístico de toda la vida” en este universo? La diferencia suele estar en la forma de pensar. Un informático o ingeniero de datos puede estar más enfocado en la eficiencia computacional, en construir algoritmos y pipelines; el estadístico, en cambio, suele centrarse en entender de dónde vienen los datos, cómo de fiables son y qué significado real tienen esas cifras. Por ejemplo, es común escuchar que en pleno auge del Big Data “los datos hablan por sí solos” y que con suficientes datos no hace falta usar estadística. Paparruchas: tener muchos datos no garantiza conclusiones acertadas si esos datos están sesgados o mal interpretados. En 1949 el famoso estadístico Frank Yates advirtió que una buena encuesta probabilística puede ser más precisa que un censo completo. ¿Por qué? Pues porque una muestra pequeña pero bien diseñada controla errores y sesgos mejor que un mar de datos descontrolados.
¿Cuál es entonces ese “toque del estadístico”? Es el del escepticismo saludable y metodológico. Donde otros ven solo volumen de datos, el estadístico se pregunta: “¿Estos datos representan bien la realidad o me están contando otra cosa?”. Por eso, el estadístico es el primero en dudar de las correlaciones raras. Las conocemos como correlaciones espúreas, fáciles de encontrar cuando tenemos suficientes datos: por ejemplo, el número de ahogamientos en piscinas en EE.UU. se relaciona con el número de películas en las que aparece Nicolas Cage (puedes explorar estas y otras correlaciones graciosas de este tipo en la página Spurious correlations). ¿Significa que las películas de Nicolas Cage son responsables de los ahogamientos? Podría parecerlo, pero es importante este mantra: correlación no implica causalidad.

Un algoritmo podría detectar estos patrones y presentarlos sin más, pero un estadístico arqueará la ceja y se preguntará si eso tiene algún sentido. Esa capacidad de distinguir señal de ruido y de buscar explicaciones causales es un aporte diferenciador frente a perfiles puramente técnicos. Eso no lo va a hacer ChatGPT, necesitamos el contexto y la sabiduría del humano. Por eso decimos que, con todo el hype del big data y la IA, el papel de los estadísticos es ahora más relevante que nunca.
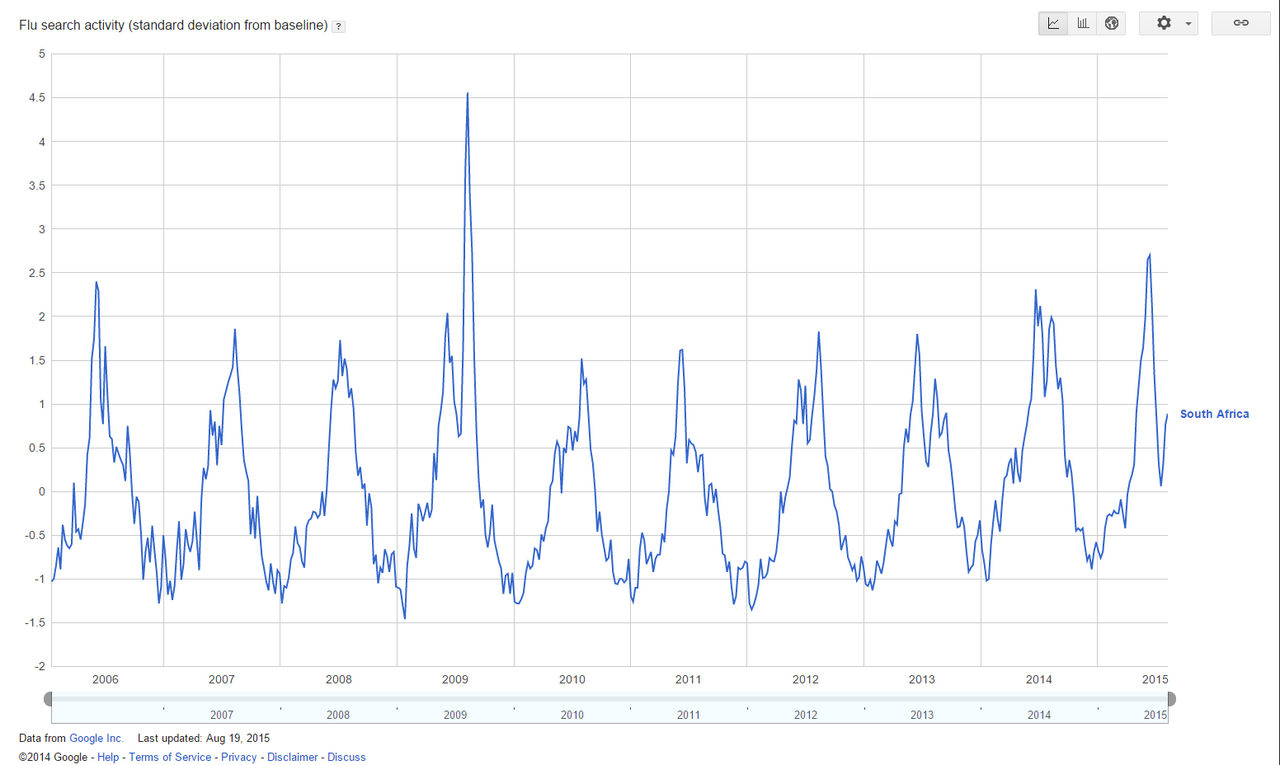
El volumen ha cambiado, eso sí: antes, el estadístico trabajaba con muestras pequeñas bajo supuestos bastante estables; ahora se enfrenta a torrentes de datos heterogéneos que cambian a gran velocidad. Por un lado, el estadístico de hoy debe ser un poco “todoterreno”: entender de bases de datos, programar en R o Python, manejar entornos distribuidos tipo Hadoop/Spark… Pero no se trata solo de sumar habilidades técnicas, sino de evolucionar el enfoque. Un ejemplo famoso fue el de Google Flu Trends: a inicios de la década de 2010, Google intentó predecir la incidencia de gripe en EE.UU. analizando las búsquedas de los usuarios. Al principio funcionó, pero cuando cambiaron las tendencias de búsqueda, el modelo empezó a fallar estrepitosamente. ¿Qué pasó? Que los modelos estadísticos clásicos de Google Flu tenían supuestos que dejaron de cumplirse, y al no recalibrarlos a tiempo, sus predicciones perdieron calidad. Este caso enseñó a muchos que en entornos cambiantes los modelos necesitan actualización constante. Aquí el estadístico ha tenido que abrazar técnicas de machine learning que permiten recalibrar modelos sobre la marcha.
Distinguiendo la música del ruido: el estadístico como brújula de datos en la era de la IA
Abrazar la IA supone riesgos: ganamos precisión, pero también opacidad. De ahí la importancia del concepto de la IA explicable (XAI): no basta con que un modelo acierte, debe poder contarse cómo llega a sus decisiones. Un estadístico no debe conformarse con que un algoritmo funcione: tiene que entenderlo, auditarlo y comprobar que no está reforzando desigualdades invisibles. En un mundo de cajas negras, su papel es abrir la tapa y traducir el razonamiento de la máquina a lenguaje humano.
Un ejemplo sonado de esto de los algoritmos de caja negra fue el de Amazon: desarrollaron una IA para seleccionar currículums, y al poco descubrieron que penalizaba a las candidatas mujeres (porque en el pasado la mayoría de contratados fueron hombres). El algoritmo aprendió ese sesgo y, por ejemplo, restaba puntos a cualquier CV que mencionara la palabra “femenino”, como “capitana del equipo femenino de ajedrez”. También daba menor puntuación a graduadas de ciertas universidades solo para mujeres. Amazon tuvo que cancelar el proyecto al ver que, pese a corregir algunos términos, la IA podía seguir inventando formas sutiles de discriminar . Este caso ilustra por qué necesitamos modelos explicables: para destapar sesgos ocultos antes de que causen daño.
Y todo parte del mismo punto: la calidad del dato. Antes de hablar de modelos o predicciones hay que asegurarse de que los datos están bien medidos, codificados y almacenados. Es el trabajo silencioso que sostiene cualquier análisis: revisar, depurar, documentar. Sin esa base, ningún modelo —por sofisticado que sea— se sostiene. De hecho, muchos fallos espectaculares de Big Data nacen de un descuido tan simple como un campo mal codificado o un valor perdido. El estadístico, en ese sentido, es un guardián del sentido común en medio del ruido. Sabe que no importa tener millones de registros si todos proceden del mismo tipo de usuario o si faltan datos clave. Por eso aplica técnicas de imputación, detección de atípicos o ponderación de muestras para acercar el conjunto de datos a la realidad que quiere estudiar. Lo importante no es el tamaño de la base, sino su representatividad: medir bien a quién y qué se mide. Incluso al visualizar esos datos, el rigor cuenta. Un gráfico mal diseñado puede distorsionar más que mil palabras. Ejes truncados, colores agresivos o efectos 3D pueden exagerar diferencias o esconder tendencias. La buena visualización no decora el dato: lo ilumina. Un gráfico honesto es aquel que ayuda a comprender sin manipular, donde la estética está al servicio de la verdad.

Esa búsqueda de sentido también explica cómo ha cambiado la propia estadística frente al Big Data. Los modelos clásicos eran como el sistema de Copérnico: quizá menos espectaculares, pero ofrecían una explicación del fenómeno. Los nuevos algoritmos, en cambio, recuerdan al Ptolomeo de los epiciclos: ajustan los datos con gran precisión, pero a veces sin entender el porqué. Hoy el reto está en combinar ambas cosas: aprovechar la potencia del aprendizaje automático sin perder el hilo lógico y explicativo que da coherencia a los resultados. El estadístico moderno es, en esencia, un científico de datos con brújula.
No solo las empresas, también los organismos oficiales han asumido ese reto. El INE y otras agencias están experimentando con registros administrativos, datos de móviles o precios escaneados en tiendas para producir estadísticas más rápidas y detalladas. Pero integrar todo eso exige el mismo equilibrio: tecnología, método y ética. El Big Data aporta velocidad; la estadística, credibilidad. Pero todo esto desemboca en la paradoja del Big Data que describió Xiao-Li Meng: cuantos más datos tenemos, más seguridad tenemos… de estar equivocados. Los sesgos no desaparecen con el tamaño; solo se amplifican con más confianza. Por eso el estadístico sigue siendo esencial: no para contar datos, sino para ponerlos en duda. En el fondo, su trabajo consiste en recordarnos que el dato es una herramienta, no un oráculo. Puede iluminar o confundir, según quién lo use. Y si el Big Data es el fuego de nuestra era, el estadístico es quien se encarga de que no acabemos quemándonos.
Este texto se ha escrito con motivo del Día Mundial de la Estadística, celebrado el 20 de octubre de 2025 en la Facultad de Ciencias de la Universidad de Granada, donde me invitaron a participar en una mesa redonda sobre estadística.

